缩放和并行处理
缩放和并行处理
许多批处理问题可以通过单线程、单进程作业来解决,因此,在考虑之前正确检查它是否满足您的需求总是一个好主意关于更复杂的实现。衡量现实作业的性能,看看是否最简单的实现首先满足您的需求。您可以读取和写入数百兆字节的文件在不到一分钟的时间内,即使使用标准硬件也是如此。
当您准备好开始实现具有一些并行处理的作业时,SpringBatch 提供了一系列选项,这些选项在本章中进行了描述,尽管一些功能将在其他地方介绍。在高层次上,有两种并行模式 加工:
-
单进程,多线程
-
多进程
这些也分为几类,如下所示:
-
多线程步骤(单进程)
-
并行步骤(单进程)
-
步骤的远程分块(多进程)
-
对步骤进行分区(单个或多个进程)
首先,我们回顾单进程选项。然后,我们回顾多进程选项。
多线程步骤
启动并行处理的最简单方法是添加一个TaskExecutor到你的步骤 配置。
例如,您可以添加tasklet如下:
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step>使用 java 配置时,一个TaskExecutor可以添加到步骤中,如以下示例所示:
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
@Bean
public Step sampleStep(TaskExecutor taskExecutor) {
return this.stepBuilderFactory.get("sampleStep")
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.build();
}
在此示例中,taskExecutor是对另一个 bean 定义的引用,该定义实现TaskExecutor接口。TaskExecutor是一个标准的 Spring 接口,因此请参阅 Spring 用户指南以获取可用 实现。 最简单的多线程TaskExecutor是一个SimpleAsyncTaskExecutor.
上述配置的结果是Step通过读取、处理、并在单独的执行线程中写入每个项目块(每个提交间隔)来执行。请注意,这意味着要处理的项目没有固定的顺序,并且块可能包含与单线程情况相比不连续的项目。 在 除了任务执行器设置的任何限制(例如它是否由线程池支持)之外,任务 let 配置中还有一个节流限制,默认为 4。您可能需要增加此限制以确保线程池得到充分利用。
例如,您可以增加 thrrottle-limit,如以下示例所示:
<step id="loading"> <tasklet
task-executor="taskExecutor"
throttle-limit="20">...</tasklet>
</step>使用 Java 配置时,构建器提供对限制的访问,如以下示例中所示:在以下示例中:
@Bean
public Step sampleStep(TaskExecutor taskExecutor) {
return this.stepBuilderFactory.get("sampleStep")
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.throttleLimit(20)
.build();
}
另请注意,在您的步骤中使用的任何池资源可能会对并发性施加限制,例如DataSource. 确保使这些资源中的池至少与步骤中所需的并发线程数一样大。
使用多线程有一些实际限制Step实现一些常见的批处理用例。许多参与者Step(例如读取器和写入器)是有状态的。如果状态未按线程隔离,则这些组件不可用于多线程Step. 特别是,大多数现成的读取器和Spring Batch 中的写入器不是为多线程使用而设计的。然而,可以使用无状态或线程安全的读取器和写入器,并且有一个示例(称为parallelJob) 在 Spring 中批处理示例,显示使用进程指示器(请参阅防止状态持久性)来跟踪数据库输入表中已处理的项。
Spring Batch 提供了一些ItemWriter和ItemReader. 通常 他们在 Javadoc 中说它们是否是线程安全的,或者您必须做些什么来避免并发环境中的问题。如果 Javadoc 中没有信息,您可以检查实现以查看是否有任何状态。如果阅读器不是线程安全的,您可以使用提供的SynchronizedItemStreamReader或在您自己的synchronizing 委托人中使用它。您可以将调用同步到read()并且只要
处理和写入是块中最昂贵的部分,你的步骤可能仍然
完成速度比单线程配置快得多。
平行步骤
只要需要并行化的应用逻辑可以拆分为不同的 职责并分配给各个步骤,然后它可以在 单一进程。并行步骤执行易于配置和使用。
例如,执行步骤(step1,step2)与step3直截了当,
如以下示例所示:
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>
<beans:bean id="taskExecutor" class="org.spr...SimpleAsyncTaskExecutor"/>使用 Java 配置时,执行步骤(step1,step2)与step3很简单,如以下示例所示:
@Bean
public Job job() {
return jobBuilderFactory.get("job")
.start(splitFlow())
.next(step4())
.build() //builds FlowJobBuilder instance
.build(); //builds Job instance
}
@Bean
public Flow splitFlow() {
return new FlowBuilder<SimpleFlow>("splitFlow")
.split(taskExecutor())
.add(flow1(), flow2())
.build();
}
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
}
@Bean
public Flow flow2() {
return new FlowBuilder<SimpleFlow>("flow2")
.start(step3())
.build();
}
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
可配置的任务执行器用于指定哪个TaskExecutor实现应用于执行各个流。默认值为SyncTaskExecutor,但异步TaskExecutor需要运行
平行。请注意,该作业确保拆分中的每个流在之前完成
聚合退出状态并转换。
有关更多详细信息,请参阅拆分流部分。
远程分块
在远程分块中,Step处理分为多个流程,
通过一些中间件相互通信。下图显示了
模式:
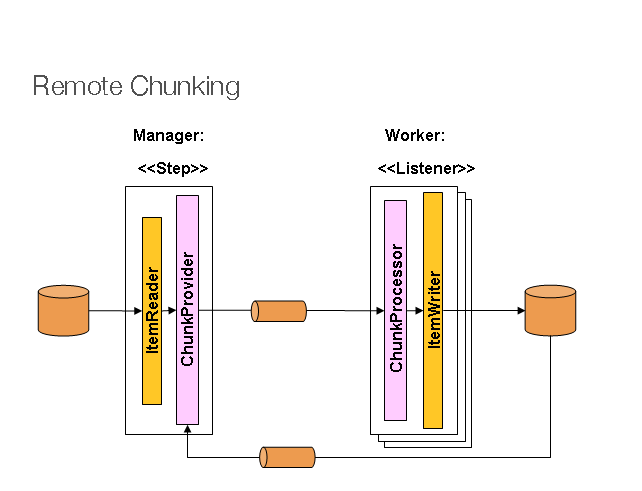
管理器组件是单个进程,工作进程是多个远程进程。 如果管理器不是瓶颈,则此模式效果最佳,因此处理必须更多 比阅读项目更昂贵(实践中经常出现这种情况)。
管理器是 Spring Batch 的实现Step使用ItemWriter取代
由一个通用版本,该版本知道如何将项目块发送到中间件作为
消息。工作线程是正在使用的任何中间件的标准侦听器(对于
例如,使用 JMS,它们将是MessageListener实现),它们的作用是
使用标准处理项块ItemWriter或ItemProcessor加ItemWriter,通过ChunkProcessor接口。使用它的优点之一
模式是读取器、处理器和写入器组件是现成的(相同
将用于步骤的本地执行)。项目是动态划分的
并且工作通过中间件共享,因此,如果听众都渴望
消费者,则负载平衡是自动的。
中间件必须是持久的,有保证的交付和每个中间件的单个消费者 消息。JMS 是显而易见的候选者,但其他选项(例如 JavaSpaces)存在于 网格计算和共享内存产品空间。
有关更多详细信息,请参阅有关 Spring Batch Integration - 远程分块的部分。
分区
Spring Batch 还提供了一个 SPI,用于对Step执行并执行它
远程。在这种情况下,远程参与者是Step实例可能同样
易于配置并用于本地处理。下图显示了
模式:
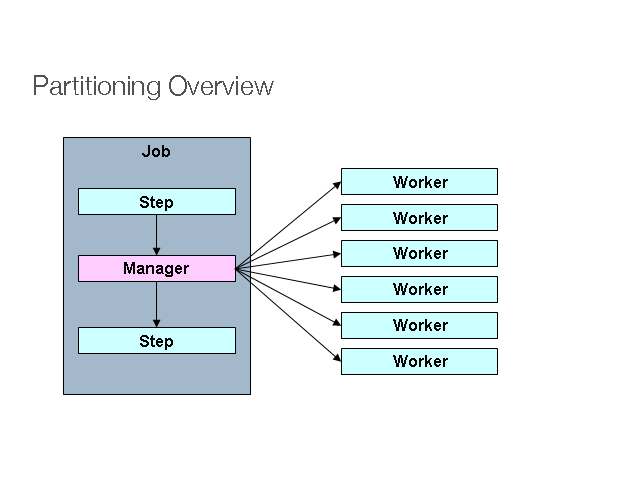
这Job在左侧运行,作为Step实例,以及其中一个Stepinstances 被标记为管理器。这张图中的工人都是一模一样的
实例Step,这实际上可以取代经理,从而导致
相同的结果Job.工作人员通常是远程服务,但
也可以是本地执行线程。经理发送给工作人员的消息
在这种模式下,不需要耐用或有保证的交货。弹簧批次
元数据中的JobRepository确保每个工作程序执行一次且仅执行一次
每Job执行。
Spring Batch 中的 SPI 由一个特殊的实现组成Step(称为PartitionStep)和两个策略接口,需要为特定的
环境。策略接口是PartitionHandler和StepExecutionSplitter,
它们的作用如下图所示:
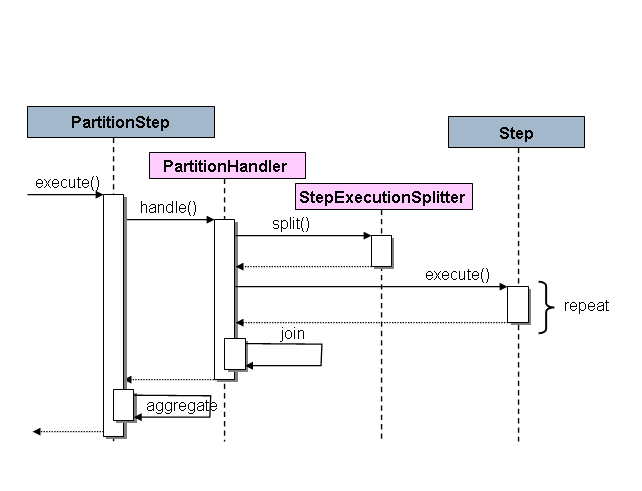
这Step在这种情况下,右边是“远程”工作人员,所以,潜在的,有
许多对象和/或进程扮演此角色,并且PartitionStep显示驾驶
执行。
以下示例显示了PartitionStep使用 XML 时的配置
配置:
<step id="step1.manager">
<partition step="step1" partitioner="partitioner">
<handler grid-size="10" task-executor="taskExecutor"/>
</partition>
</step>以下示例显示了PartitionStep使用 Java 时的配置
配置:
@Bean
public Step step1Manager() {
return stepBuilderFactory.get("step1.manager")
.<String, String>partitioner("step1", partitioner())
.step(step1())
.gridSize(10)
.taskExecutor(taskExecutor())
.build();
}
类似于多线程步骤的throttle-limit属性,则grid-size属性可防止任务执行器因来自单个
步。
有一个简单的示例可以在 Spring 的单元测试套件中复制和扩展
批处理
Samples(请参阅partition*Job.xml配置)。
Spring Batch 为名为“step1:partition0”的分区创建步骤执行,因此
上。为了保持一致性,许多人更喜欢将管理器步骤称为“step1:manager”。您可以
为步骤使用别名(通过指定name属性而不是id属性)。
分区处理程序
这PartitionHandler是知道远程处理结构的组件,或
网格环境。它能够发送StepExecution对远程的请求Step实例,以某种特定于结构的格式包装,例如 DTO。它不必知道
如何拆分输入数据或如何聚合多个Step执行。
一般来说,它可能也不需要了解弹性或故障转移,
因为在许多情况下,这些都是织物的特征。无论如何,Spring Batch 总是
提供独立于结构的可重启性。失败的Job可以随时重新启动
只有失败的Steps被重新执行。
这PartitionHandler接口可以有针对各种
结构类型,包括简单的 RMI 远程处理、EJB 远程处理、自定义 Web 服务、JMS、Java
空间、共享内存网格(如 Terracotta 或 Coherence)和网格执行结构
(如 GridGain)。Spring Batch 不包含任何专有网格的实现
或远程处理结构。
但是,Spring Batch 确实提供了一个有用的实现PartitionHandler那
执行Step实例在本地的单独执行线程中,使用TaskExecutor春季战略。该实现称为TaskExecutorPartitionHandler.
这TaskExecutorPartitionHandler是配置了 XML 的步骤的默认值
命名空间。它也可以显式配置,如
以下示例:
<step id="step1.manager">
<partition step="step1" handler="handler"/>
</step>
<bean class="org.spr...TaskExecutorPartitionHandler">
<property name="taskExecutor" ref="taskExecutor"/>
<property name="step" ref="step1" />
<property name="gridSize" value="10" />
</bean>这TaskExecutorPartitionHandler可以在 Java 配置中显式配置,
如以下示例所示:
@Bean
public Step step1Manager() {
return stepBuilderFactory.get("step1.manager")
.partitioner("step1", partitioner())
.partitionHandler(partitionHandler())
.build();
}
@Bean
public PartitionHandler partitionHandler() {
TaskExecutorPartitionHandler retVal = new TaskExecutorPartitionHandler();
retVal.setTaskExecutor(taskExecutor());
retVal.setStep(step1());
retVal.setGridSize(10);
return retVal;
}
这gridSize属性确定要创建的单独步骤执行的数量,因此
它可以与TaskExecutor.或者,它
可以设置为大于可用线程数,这使得
工作更小。
这TaskExecutorPartitionHandler对于 IO 密集型Step实例,例如
将大量文件复制或将文件系统复制到内容管理中
系统。它还可以通过提供Step实现
这是远程调用的代理(例如使用 Spring Remoting)。
分区器
这Partitioner有一个更简单的职责:生成执行上下文作为输入仅用于新步骤执行的参数(无需担心重新启动)。它有一个single 方法,如以下接口定义所示:
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
}
此方法的返回值为每个步骤执行关联一个唯一的名称(String)的输入参数,其输入参数的形式为ExecutionContext. 名称显示稍后在批处理元数据中作为分区StepExecutions.这ExecutionContext只是一个名称-值对的包,因此它可能包含一系列主键、行号或输入文件的位置。远程Step然后 通常使用#{…}占位符(步骤中的后期绑定scope),如下一节所示。
步骤执行的名称(Map返回者Partitioner) 需要在Job但没有任何其他特定的 要求。 最简单的方法(并使名称对用户有意义)是使用前缀+后缀命名约定,其中前缀是正在执行的步骤的名称(它本身在Job),后缀只是一个 计数器。 有一个SimplePartitioner在使用此约定的框架中。
一个名为PartitionNameProvider可用于提供分区名称与分区本身分开。如果Partitioner实现此接口,则在重新启动时,仅查询名称。如果分区成本高昂,这可能是一个有用的优化。由PartitionNameProvider必须 匹配Partitioner.
将输入数据绑定到步骤
对于执行的步骤来说,这是非常有效的PartitionHandler具有相同的配置,并在运行时从ExecutionContext. 这很容易通过 Spring Batch 的 StepScope 功能做到(在 Late Binding 部分有更详细的介绍)。 为 例如,如果Partitioner创建ExecutionContext具有属性键的实例 叫fileName,指向每个步骤调用的不同文件(或目录), 这Partitioner输出可能类似于下表的内容:
步骤执行名称(键) |
ExecutionContext(值) |
文件副本:分区0 |
文件名=/home/data/one |
文件副本:分区 1 |
文件名=/home/data/two |
文件复制:分区2 |
文件名=/home/data/three |
然后,可以使用对执行上下文的延迟绑定将文件名绑定到步骤。
以下示例显示了如何在 XML 中定义后期绑定:
<bean id="itemReader" scope="step"
class="org.spr...MultiResourceItemReader">
<property name="resources" value="#{stepExecutionContext[fileName]}/*"/>
</bean>以下示例显示了如何在 Java 中定义后期绑定:
@Bean
public MultiResourceItemReader itemReader(
@Value("#{stepExecutionContext['fileName']}/*") Resource [] resources) {
return new MultiResourceItemReaderBuilder<String>()
.delegate(fileReader())
.name("itemReader")
.resources(resources)
.build();
}