虽然我们在上一节中描述的 AMQP 模型是通用的,适用于所有实现,但当我们进入资源管理时,详细信息是特定于代理实现的。 因此,在本节中,我们将重点介绍仅存在于“spring-rabbit”模块中的代码,因为此时 RabbitMQ 是唯一受支持的实现。
用于管理与 RabbitMQ 代理的连接的核心组件是接口。
实现的职责是提供 的实例,该实例是 的包装器。ConnectionFactoryConnectionFactoryorg.springframework.amqp.rabbit.connection.Connectioncom.rabbitmq.client.Connection
选择连接工厂
有三种连接工厂可供选择
-
PooledChannelConnectionFactory -
ThreadChannelConnectionFactory -
CachingConnectionFactory
前两个是在 2.3 版中添加的。
对于大多数用例,应使用 。
如果要确保严格的消息排序而无需使用作用域操作,则可以使用 。
这与它类似,因为它使用单个连接和一个通道池。
它的实现更简单,但不支持相关的发布者确认。CachingConnectionFactoryThreadChannelConnectionFactoryPooledChannelConnectionFactoryCachingConnectionFactory
所有三个工厂都支持简单的发布者确认。
现在,在将 a 配置为使用单独的连接时,从 V2.3.2 开始,可以将发布连接工厂配置为其他类型。
默认情况下,发布工厂是相同的类型,在主工厂上设置的任何属性也会传播到发布工厂。RabbitTemplate
从版本 3.1 开始,包含属性,该属性支持连接模块中的回退策略。
目前,支持处理达到限制时发生的异常的行为,实现基于尝试和间隔的回退策略。AbstractConnectionFactoryconnectionCreatingBackOffcreateChannel()channelMax
PooledChannelConnectionFactory
此工厂基于 Apache Pool2 管理单个连接和两个通道池。
一个池用于事务性通道,另一个池用于非事务性通道。
池是具有默认配置的池;提供回调以配置池;有关详细信息,请参阅 Apache 文档。GenericObjectPool
Apache jar 必须在类路径上才能使用此工厂。commons-pool2
@Bean
PooledChannelConnectionFactory pcf() throws Exception {
ConnectionFactory rabbitConnectionFactory = new ConnectionFactory();
rabbitConnectionFactory.setHost("localhost");
PooledChannelConnectionFactory pcf = new PooledChannelConnectionFactory(rabbitConnectionFactory);
pcf.setPoolConfigurer((pool, tx) -> {
if (tx) {
// configure the transactional pool
}
else {
// configure the non-transactional pool
}
});
return pcf;
}ThreadChannelConnectionFactory
此工厂管理单个连接和两个 s,一个用于事务通道,另一个用于非事务通道。
此工厂确保同一线程上的所有操作都使用相同的通道(只要它保持打开状态)。
这有助于严格的消息排序,而无需作用域操作。
为了避免内存泄漏,如果应用程序使用许多短期线程,则必须调用工厂来释放通道资源。
从版本 2.3.7 开始,一个线程可以将其通道转移到另一个线程。
有关更多信息,请参见多线程环境中的严格消息排序。ThreadLocalcloseThreadChannel()
CachingConnectionFactory
提供的第三个实现是 ,默认情况下,它建立可由应用程序共享的单个连接代理。
由于使用 AMQP 进行消息传递的“工作单元”实际上是一个“通道”(在某些方面,这类似于 JMS 中连接和会话之间的关系),因此可以共享连接。
连接实例提供了一个方法。
该实现支持缓存这些通道,并根据通道是否为事务性通道维护单独的缓存。
创建 的实例时,可以通过构造函数提供“主机名”。
您还应该提供“username”和“password”属性。
若要配置通道缓存的大小(默认为 25),可以调用该方法。CachingConnectionFactorycreateChannelCachingConnectionFactoryCachingConnectionFactorysetChannelCacheSize()
从版本 1.3 开始,您可以配置缓存连接以及仅缓存通道。
在这种情况下,每次调用都会创建一个新连接(或从缓存中检索空闲连接)。
关闭连接会将其返回到缓存(如果尚未达到缓存大小)。
在此类连接上创建的通道也会被缓存。
在某些环境中,例如从 HA 集群使用单独的连接可能很有用,在
与负载均衡器结合使用,以连接到不同的集群成员等。
若要缓存连接,请将 设置为 。CachingConnectionFactorycreateConnection()cacheModeCacheMode.CONNECTION
| 这不会限制连接数。 相反,它指定允许多少个空闲打开的连接。 |
从版本 1.5.5 开始,将提供一个名为的新属性。
设置此属性时,它会限制允许的连接总数。
设置后,如果达到限制,则用于等待连接变为空闲状态。
如果超过时间,则抛出 an。connectionLimitchannelCheckoutTimeLimitAmqpTimeoutException
|
当缓存模式为 时,自动声明队列等
(请参阅交换、队列和绑定的自动声明)不受支持。 此外,在撰写本文时,默认情况下,库会为每个连接创建一个固定的线程池(默认大小:线程)。
使用大量连接时,应考虑在 .
然后,所有连接都可以使用同一个执行器,并且可以共享其线程。
执行程序的线程池应是无限制的,或针对预期用途进行适当设置(通常,每个连接至少一个线程)。
如果在每个连接上创建多个通道,则池大小会影响并发性,因此可变(或简单缓存)线程池执行器将是最合适的。 |
重要的是要了解缓存大小(默认情况下)不是限制,而只是可以缓存的通道数。 如果缓存大小为 10,则实际上可以使用任意数量的通道。 如果使用的通道超过 10 个,并且它们都返回到缓存中,则有 10 个通道进入缓存。 其余部分在物理上是封闭的。
从版本 1.6 开始,默认通道缓存大小已从 1 增加到 25。 在大容量、多线程环境中,较小的缓存意味着通道的创建和关闭速率很高。 增加默认缓存大小可以避免此开销。 您应该通过 RabbitMQ 管理 UI 监控正在使用的通道,并考虑进一步增加缓存大小,如果您 查看许多正在创建和关闭的频道。 缓存仅按需增长(以满足应用程序的并发要求),因此此更改不会 影响现有的小批量应用程序。
从版本 1.4.2 开始,具有一个名为 的属性。
当此属性大于零时,将成为对可以在连接上创建的通道数的限制。
如果达到限制,则调用线程将阻塞,直到通道可用或达到此超时,在这种情况下将引发 a。CachingConnectionFactorychannelCheckoutTimeoutchannelCacheSizeAmqpTimeoutException
框架内使用的通道(例如,)可靠地返回到缓存中。
如果在框架之外创建通道,(例如,
通过直接访问连接并调用),您必须可靠地(通过关闭)返回它们,也许在一个块中,以避免通道耗尽。RabbitTemplatecreateChannel()finally |
下面的示例演示如何创建一个新的:connection
CachingConnectionFactory connectionFactory = new CachingConnectionFactory("somehost");
connectionFactory.setUsername("guest");
connectionFactory.setPassword("guest");
Connection connection = connectionFactory.createConnection();使用 XML 时,配置可能如以下示例所示:
<bean id="connectionFactory"
class="org.springframework.amqp.rabbit.connection.CachingConnectionFactory">
<constructor-arg value="somehost"/>
<property name="username" value="guest"/>
<property name="password" value="guest"/>
</bean>还有一个实现仅在框架的单元测试代码中可用。
它比 更简单,因为它不缓存通道,但由于缺乏性能和弹性,它不适合简单测试之外的实际使用。
如果出于某种原因需要实现自己的基类,基类可能会提供一个很好的起点。SingleConnectionFactoryCachingConnectionFactoryConnectionFactoryAbstractConnectionFactory |
使用 rabbit 命名空间可以快速方便地创建一个 A,如下所示:ConnectionFactory
<rabbit:connection-factory id="connectionFactory"/>在大多数情况下,这种方法是可取的,因为框架可以为你选择最佳默认值。
创建的实例是 .
请记住,通道的默认缓存大小为 25。
如果要缓存更多通道,请通过设置“channelCacheSize”属性来设置更大的值。
在 XML 中,它如下所示:CachingConnectionFactory
<bean id="connectionFactory"
class="org.springframework.amqp.rabbit.connection.CachingConnectionFactory">
<constructor-arg value="somehost"/>
<property name="username" value="guest"/>
<property name="password" value="guest"/>
<property name="channelCacheSize" value="50"/>
</bean>此外,使用命名空间,您可以添加“channel-cache-size”属性,如下所示:
<rabbit:connection-factory
id="connectionFactory" channel-cache-size="50"/>默认缓存模式为 ,但您可以将其配置为缓存连接。
在下面的例子中,我们使用:CHANNELconnection-cache-size
<rabbit:connection-factory
id="connectionFactory" cache-mode="CONNECTION" connection-cache-size="25"/>您可以使用命名空间提供主机和端口属性,如下所示:
<rabbit:connection-factory
id="connectionFactory" host="somehost" port="5672"/>或者,如果在群集环境中运行,则可以使用 addresses 属性,如下所示:
<rabbit:connection-factory
id="connectionFactory" addresses="host1:5672,host2:5672" address-shuffle-mode="RANDOM"/>有关 的信息,请参见 连接到集群。address-shuffle-mode
以下示例包含一个自定义线程工厂,该工厂在线程名称前加上:rabbitmq-
<rabbit:connection-factory id="multiHost" virtual-host="/bar" addresses="host1:1234,host2,host3:4567"
thread-factory="tf"
channel-cache-size="10" username="user" password="password" />
<bean id="tf" class="org.springframework.scheduling.concurrent.CustomizableThreadFactory">
<constructor-arg value="rabbitmq-" />
</bean>| 这不会限制连接数。 相反,它指定允许多少个空闲打开的连接。 |
|
当缓存模式为 时,自动声明队列等
(请参阅交换、队列和绑定的自动声明)不受支持。 此外,在撰写本文时,默认情况下,库会为每个连接创建一个固定的线程池(默认大小:线程)。
使用大量连接时,应考虑在 .
然后,所有连接都可以使用同一个执行器,并且可以共享其线程。
执行程序的线程池应是无限制的,或针对预期用途进行适当设置(通常,每个连接至少一个线程)。
如果在每个连接上创建多个通道,则池大小会影响并发性,因此可变(或简单缓存)线程池执行器将是最合适的。 |
框架内使用的通道(例如,)可靠地返回到缓存中。
如果在框架之外创建通道,(例如,
通过直接访问连接并调用),您必须可靠地(通过关闭)返回它们,也许在一个块中,以避免通道耗尽。RabbitTemplatecreateChannel()finally |
还有一个实现仅在框架的单元测试代码中可用。
它比 更简单,因为它不缓存通道,但由于缺乏性能和弹性,它不适合简单测试之外的实际使用。
如果出于某种原因需要实现自己的基类,基类可能会提供一个很好的起点。SingleConnectionFactoryCachingConnectionFactoryConnectionFactoryAbstractConnectionFactory |
命名连接
从版本 1.7 开始,提供了用于注入 .
生成的名称用于特定于应用程序标识目标 RabbitMQ 连接。
如果 RabbitMQ 服务器支持连接名称,则该连接名称将显示在管理 UI 中。
此值不必是唯一的,也不能用作连接标识符,例如,在 HTTP API 请求中。
此值应该是人类可读的,并且是键下的一部分。
您可以使用简单的 Lambda,如下所示:ConnectionNameStrategyAbstractionConnectionFactoryClientPropertiesconnection_name
connectionFactory.setConnectionNameStrategy(connectionFactory -> "MY_CONNECTION");该参数可用于通过某些逻辑来区分目标连接名称。
默认情况下,的 、表示对象的十六进制字符串和内部计数器用于生成 .
命名空间组件也随属性一起提供。ConnectionFactorybeanNameAbstractConnectionFactoryconnection_name<rabbit:connection-factory>connection-name-strategy
的实现将连接名称设置为应用程序属性。
您可以将其声明为 a 并将其注入到连接工厂中,如以下示例所示:SimplePropertyValueConnectionNameStrategy@Bean
@Bean
public SimplePropertyValueConnectionNameStrategy cns() {
return new SimplePropertyValueConnectionNameStrategy("spring.application.name");
}
@Bean
public ConnectionFactory rabbitConnectionFactory(ConnectionNameStrategy cns) {
CachingConnectionFactory connectionFactory = new CachingConnectionFactory();
...
connectionFactory.setConnectionNameStrategy(cns);
return connectionFactory;
}该属性必须存在于应用程序上下文的 .Environment
使用 Spring Boot 及其自动配置的连接工厂时,只需声明 .
Boot 会自动检测 Bean 并将其连接到工厂。ConnectionNameStrategy@Bean |
使用 Spring Boot 及其自动配置的连接工厂时,只需声明 .
Boot 会自动检测 Bean 并将其连接到工厂。ConnectionNameStrategy@Bean |
阻塞的连接和资源限制
连接可能会被阻止,无法与内存警报对应的代理进行交互。
从版本 2.0 开始,可以提供实例,以通知连接阻止和取消阻止事件。
此外,通过其内部实现分别发出 a 和 。
这些允许您提供应用程序逻辑,以便对代理上的问题做出适当的反应,并(例如)采取一些纠正措施。org.springframework.amqp.rabbit.connection.Connectioncom.rabbitmq.client.BlockedListenerAbstractConnectionFactoryConnectionBlockedEventConnectionUnblockedEventBlockedListener
当应用程序配置为单个 时,就像默认情况下使用 Spring Boot 自动配置一样,当连接被代理阻止时,应用程序将停止工作。
当它被经纪人阻止时,它的任何客户都会停止工作。
如果我们在同一个应用程序中有生产者和消费者,那么当生产者阻止连接(因为 Broker 上不再有资源)并且消费者无法释放它们(因为连接被阻止)时,我们最终可能会陷入死锁。
为了缓解这个问题,我们建议再增加一个具有相同选项的单独实例——一个用于生产者,一个用于消费者。
对于在使用者线程上执行的事务生产者来说,不可能单独使用,因为它们应该重用与使用者事务关联的事务。CachingConnectionFactoryCachingConnectionFactoryCachingConnectionFactoryChannel |
从版本 2.0.2 开始,除非正在使用事务,否则具有自动使用第二个连接工厂的配置选项。
有关详细信息,请参阅使用单独的连接。
对于发布者连接与主策略相同,并附加到调用方法的结果中。RabbitTemplateConnectionNameStrategy.publisher
从版本 1.7.7 开始,将提供 an,当无法创建 an 时(例如,因为达到限制并且缓存中没有可用通道)时会抛出该 an。
您可以在 在回退后使用此异常来恢复操作。AmqpResourceNotAvailableExceptionSimpleConnection.createChannel()ChannelchannelMaxRetryPolicy
当应用程序配置为单个 时,就像默认情况下使用 Spring Boot 自动配置一样,当连接被代理阻止时,应用程序将停止工作。
当它被经纪人阻止时,它的任何客户都会停止工作。
如果我们在同一个应用程序中有生产者和消费者,那么当生产者阻止连接(因为 Broker 上不再有资源)并且消费者无法释放它们(因为连接被阻止)时,我们最终可能会陷入死锁。
为了缓解这个问题,我们建议再增加一个具有相同选项的单独实例——一个用于生产者,一个用于消费者。
对于在使用者线程上执行的事务生产者来说,不可能单独使用,因为它们应该重用与使用者事务关联的事务。CachingConnectionFactoryCachingConnectionFactoryCachingConnectionFactoryChannel |
配置基础客户端连接工厂
使用 Rabbit 客户端的实例。
在 上设置等效属性时,会传递许多配置属性(例如,、和)。
若要设置其他属性(例如),可以定义 Rabbit 工厂的实例,并使用 .
使用命名空间时(如前所述),您需要在属性中提供对已配置工厂的引用。
为方便起见,提供了工厂 Bean 来帮助在 Spring 应用程序上下文中配置连接工厂,如下一节所述。CachingConnectionFactoryConnectionFactoryhostportuserNamepasswordrequestedHeartBeatconnectionTimeoutCachingConnectionFactoryclientPropertiesCachingConnectionFactoryconnection-factory
<rabbit:connection-factory
id="connectionFactory" connection-factory="rabbitConnectionFactory"/>默认情况下,4.0.x 客户端启用自动恢复。
虽然与此功能兼容,但 Spring AMQP 有自己的恢复机制,通常不需要客户端恢复功能。
我们建议禁用自动恢复,以避免在代理可用但连接尚未恢复时获取实例。
您可能会注意到此异常,例如,当在 中配置了 a 时,即使故障转移到集群中的另一个代理也是如此。
由于自动恢复连接在计时器上恢复,因此使用 Spring AMQP 的恢复机制可以更快地恢复连接。
从版本 1.7.1 开始,Spring AMQP 禁用自动恢复,除非您显式创建自己的 RabbitMQ 连接工厂并将其提供给 .
默认情况下,由 创建的 RabbitMQ 实例也禁用了该选项。amqp-clientAutoRecoverConnectionNotCurrentlyOpenExceptionRetryTemplateRabbitTemplateamqp-clientCachingConnectionFactoryConnectionFactoryRabbitConnectionFactoryBean |
默认情况下,4.0.x 客户端启用自动恢复。
虽然与此功能兼容,但 Spring AMQP 有自己的恢复机制,通常不需要客户端恢复功能。
我们建议禁用自动恢复,以避免在代理可用但连接尚未恢复时获取实例。
您可能会注意到此异常,例如,当在 中配置了 a 时,即使故障转移到集群中的另一个代理也是如此。
由于自动恢复连接在计时器上恢复,因此使用 Spring AMQP 的恢复机制可以更快地恢复连接。
从版本 1.7.1 开始,Spring AMQP 禁用自动恢复,除非您显式创建自己的 RabbitMQ 连接工厂并将其提供给 .
默认情况下,由 创建的 RabbitMQ 实例也禁用了该选项。amqp-clientAutoRecoverConnectionNotCurrentlyOpenExceptionRetryTemplateRabbitTemplateamqp-clientCachingConnectionFactoryConnectionFactoryRabbitConnectionFactoryBean |
RabbitConnectionFactoryBean和配置 SSL
从版本 1.4 开始,提供了方便的功能,以便使用依赖注入在底层客户端连接工厂上方便地配置 SSL 属性。
其他设置者委托给基础工厂。
以前,您必须以编程方式配置 SSL 选项。
以下示例演示如何配置:RabbitConnectionFactoryBeanRabbitConnectionFactoryBean
@Bean
RabbitConnectionFactoryBean rabbitConnectionFactory() {
RabbitConnectionFactoryBean factoryBean = new RabbitConnectionFactoryBean();
factoryBean.setUseSSL(true);
factoryBean.setSslPropertiesLocation(new ClassPathResource("secrets/rabbitSSL.properties"));
return factoryBean;
}
@Bean
CachingConnectionFactory connectionFactory(ConnectionFactory rabbitConnectionFactory) {
CachingConnectionFactory ccf = new CachingConnectionFactory(rabbitConnectionFactory);
ccf.setHost("...");
// ...
return ccf;
}spring.rabbitmq.ssl.enabled:true
spring.rabbitmq.ssl.keyStore=...
spring.rabbitmq.ssl.keyStoreType=jks
spring.rabbitmq.ssl.keyStorePassword=...
spring.rabbitmq.ssl.trustStore=...
spring.rabbitmq.ssl.trustStoreType=jks
spring.rabbitmq.ssl.trustStorePassword=...
spring.rabbitmq.host=...
...<rabbit:connection-factory id="rabbitConnectionFactory"
connection-factory="clientConnectionFactory"
host="${host}"
port="${port}"
virtual-host="${vhost}"
username="${username}" password="${password}" />
<bean id="clientConnectionFactory"
class="org.springframework.amqp.rabbit.connection.RabbitConnectionFactoryBean">
<property name="useSSL" value="true" />
<property name="sslPropertiesLocation" value="classpath:secrets/rabbitSSL.properties"/>
</bean>有关配置 SSL 的信息,请参阅 RabbitMQ 文档。
省略 and 配置以在不进行证书验证的情况下通过 SSL 进行连接。
下一个示例演示如何提供密钥和信任存储配置。keyStoretrustStore
该属性是一个 Spring,指向包含以下键的属性文件:sslPropertiesLocationResource
keyStore=file:/secret/keycert.p12
trustStore=file:/secret/trustStore
keyStore.passPhrase=secret
trustStore.passPhrase=secret和 是 Spring 指向商店。
通常,此属性文件由操作系统保护,应用程序具有读取访问权限。keyStoretruststoreResources
从 Spring AMQP 版本 1.5 开始,您可以直接在工厂 Bean 上设置这些属性。
如果同时提供离散属性 和 ,则后者中的属性将覆盖
离散值。sslPropertiesLocation
从版本 2.0 开始,默认情况下会验证服务器证书,因为它更安全。
如果出于某种原因希望跳过此验证,请将工厂 Bean 的属性设置为 。
从版本 2.1 开始,现在默认调用。
若要恢复到以前的行为,请将属性设置为 。skipServerCertificateValidationtrueRabbitConnectionFactoryBeanenableHostnameVerification()enableHostnameVerificationfalse |
从 V2.2.5 开始,工厂 Bean 将始终默认使用 TLS v1.2;以前,它在某些情况下使用 v1.1,在其他情况下使用 v1.2(取决于其他属性)。
如果出于某种原因需要使用 v1.1,请设置属性: 。sslAlgorithmsetSslAlgorithm("TLSv1.1") |
从版本 2.0 开始,默认情况下会验证服务器证书,因为它更安全。
如果出于某种原因希望跳过此验证,请将工厂 Bean 的属性设置为 。
从版本 2.1 开始,现在默认调用。
若要恢复到以前的行为,请将属性设置为 。skipServerCertificateValidationtrueRabbitConnectionFactoryBeanenableHostnameVerification()enableHostnameVerificationfalse |
从 V2.2.5 开始,工厂 Bean 将始终默认使用 TLS v1.2;以前,它在某些情况下使用 v1.1,在其他情况下使用 v1.2(取决于其他属性)。
如果出于某种原因需要使用 v1.1,请设置属性: 。sslAlgorithmsetSslAlgorithm("TLSv1.1") |
连接到集群
若要连接到群集,请在 :addressesCachingConnectionFactory
@Bean
public CachingConnectionFactory ccf() {
CachingConnectionFactory ccf = new CachingConnectionFactory();
ccf.setAddresses("host1:5672,host2:5672,host3:5672");
return ccf;
}从版本 3.0 开始,每当建立新连接时,基础连接工厂将尝试通过选择随机地址来连接到主机。
若要恢复到以前尝试从第一个连接到最后一个的行为,请将该属性设置为 。addressShuffleModeAddressShuffleMode.NONE
从 2.3 版本开始,添加了随机播放模式,这意味着在创建连接后,第一个地址将移至末尾。
如果您希望从所有节点上的所有分片中使用,您可能希望将此模式与 RabbitMQ 分片插件一起使用,并具有合适的并发性。INORDERCacheMode.CONNECTION
@Bean
public CachingConnectionFactory ccf() {
CachingConnectionFactory ccf = new CachingConnectionFactory();
ccf.setAddresses("host1:5672,host2:5672,host3:5672");
ccf.setAddressShuffleMode(AddressShuffleMode.INORDER);
return ccf;
}路由连接工厂
从 1.3 版开始,引入了 。
此工厂提供了一种机制,用于配置多个映射,并在运行时由某个站点确定目标。
通常,该实现会检查线程绑定上下文。
为方便起见,Spring AMQP 提供了 ,它从 获取当前线程绑定。
以下示例演示如何在 XML 和 Java 中配置 a:AbstractRoutingConnectionFactoryConnectionFactoriesConnectionFactorylookupKeySimpleRoutingConnectionFactorylookupKeySimpleResourceHolderSimpleRoutingConnectionFactory
<bean id="connectionFactory"
class="org.springframework.amqp.rabbit.connection.SimpleRoutingConnectionFactory">
<property name="targetConnectionFactories">
<map>
<entry key="#{connectionFactory1.virtualHost}" ref="connectionFactory1"/>
<entry key="#{connectionFactory2.virtualHost}" ref="connectionFactory2"/>
</map>
</property>
</bean>
<rabbit:template id="template" connection-factory="connectionFactory" />public class MyService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void service(String vHost, String payload) {
SimpleResourceHolder.bind(rabbitTemplate.getConnectionFactory(), vHost);
rabbitTemplate.convertAndSend(payload);
SimpleResourceHolder.unbind(rabbitTemplate.getConnectionFactory());
}
}使用后解绑资源很重要。
有关更多信息,请参见 JavaDoc。AbstractRoutingConnectionFactory
从版本 1.4 开始,支持 SpEL 和属性,这些属性在每个 AMQP 协议交互操作(、、或)上进行评估,解析为提供的 .
您可以使用 Bean 引用,例如在表达式中。
对于操作,要发送的消息是根评估对象。
对于操作,是根评估对象。RabbitTemplatesendConnectionFactorySelectorExpressionreceiveConnectionFactorySelectorExpressionsendsendAndReceivereceivereceiveAndReplylookupKeyAbstractRoutingConnectionFactory@vHostResolver.getVHost(#root)sendreceivequeueName
路由算法如下:如果选择器表达式是 或被计算为 或 提供的不是 的实例,则一切都像以前一样工作,依赖于提供的实现。
如果评估结果不是 ,但没有目标,并且配置了 。
在 的情况下,它确实回退到其基于 的实现。
但是,如果 ,则抛出 an。nullnullConnectionFactoryAbstractRoutingConnectionFactoryConnectionFactorynullConnectionFactorylookupKeyAbstractRoutingConnectionFactorylenientFallback = trueAbstractRoutingConnectionFactoryroutingdetermineCurrentLookupKey()lenientFallback = falseIllegalStateException
命名空间支持还提供组件的 and 属性。send-connection-factory-selector-expressionreceive-connection-factory-selector-expression<rabbit:template>
此外,从版本 1.4 开始,可以在侦听器容器中配置路由连接工厂。
在这种情况下,队列名称列表将用作查找键。
例如,如果将容器配置为 ,则查找键为 (请注意,键中没有空格)。setQueueNames("thing1", "thing2")[thing1,thing]"
从版本 1.6.9 开始,您可以在侦听器容器上使用向查找键添加限定符。
例如,这样做可以侦听具有相同名称但位于不同虚拟主机中的队列(每个虚拟主机都有一个连接工厂)。setLookupKeyQualifier
例如,使用查找键限定符和侦听队列的容器,可以向其注册目标连接工厂的查找键可以是 。thing1thing2thing1[thing2]
| 目标(和默认连接工厂,如果提供)必须具有相同的发布者确认和返回设置。 请参阅发布者确认和返回。 |
从版本 2.4.4 开始,可以禁用此验证。
如果确认和返回之间的值需要不相等,则可以使用来切换验证。
请注意,添加到的第一个连接工厂将确定 和 的常规值。AbstractRoutingConnectionFactory#setConsistentConfirmsReturnsAbstractRoutingConnectionFactoryconfirmsreturns
如果您遇到要检查的某些消息确认/返回而其他消息没有确认/返回的情况,这可能会很有用。 例如:
@Bean
public RabbitTemplate rabbitTemplate() {
final com.rabbitmq.client.ConnectionFactory cf = new com.rabbitmq.client.ConnectionFactory();
cf.setHost("localhost");
cf.setPort(5672);
CachingConnectionFactory cachingConnectionFactory = new CachingConnectionFactory(cf);
cachingConnectionFactory.setPublisherConfirmType(CachingConnectionFactory.ConfirmType.CORRELATED);
PooledChannelConnectionFactory pooledChannelConnectionFactory = new PooledChannelConnectionFactory(cf);
final Map<Object, ConnectionFactory> connectionFactoryMap = new HashMap<>(2);
connectionFactoryMap.put("true", cachingConnectionFactory);
connectionFactoryMap.put("false", pooledChannelConnectionFactory);
final AbstractRoutingConnectionFactory routingConnectionFactory = new SimpleRoutingConnectionFactory();
routingConnectionFactory.setConsistentConfirmsReturns(false);
routingConnectionFactory.setDefaultTargetConnectionFactory(pooledChannelConnectionFactory);
routingConnectionFactory.setTargetConnectionFactories(connectionFactoryMap);
final RabbitTemplate rabbitTemplate = new RabbitTemplate(routingConnectionFactory);
final Expression sendExpression = new SpelExpressionParser().parseExpression(
"messageProperties.headers['x-use-publisher-confirms'] ?: false");
rabbitTemplate.setSendConnectionFactorySelectorExpression(sendExpression);
}这样,带有标头的消息将通过缓存连接发送,您可以确保消息传递。
有关确保邮件传递的详细信息,请参阅发布者确认和返回。x-use-publisher-confirms: true
| 目标(和默认连接工厂,如果提供)必须具有相同的发布者确认和返回设置。 请参阅发布者确认和返回。 |
队列亲和力和LocalizedQueueConnectionFactory
在集群中使用 HA 队列时,为了获得最佳性能,您可能需要连接到物理代理
潜在顾客队列所在的位置。
可以配置多个代理地址。
这是故障转移,客户端尝试按照配置的顺序进行连接。
它使用管理插件提供的 REST API 来确定哪个节点是队列的引线。
然后,它创建(或从缓存中检索)仅连接到该节点。
如果连接失败,则确定新的引导节点,使用者连接到该节点。
配置了默认连接工厂,以防无法确定队列的物理位置,在这种情况下,它会正常连接到集群。CachingConnectionFactoryAddressShuffleModeLocalizedQueueConnectionFactoryCachingConnectionFactoryLocalizedQueueConnectionFactory
是 a,并且使用队列名称作为查找键,如上面的路由连接工厂中所述。LocalizedQueueConnectionFactoryRoutingConnectionFactorySimpleMessageListenerContainer
因此(使用队列名称进行查找),仅当容器配置为侦听单个队列时,才能使用 。LocalizedQueueConnectionFactory |
| 必须在每个节点上启用 RabbitMQ 管理插件。 |
此连接工厂适用于长期连接,例如 .
它不适用于短连接使用,例如,因为在建立连接之前调用 REST API 的开销。
此外,对于发布操作,队列是未知的,并且消息无论如何都会发布到所有集群成员,因此查找节点的逻辑几乎没有价值。SimpleMessageListenerContainerRabbitTemplate |
以下示例配置显示了如何配置工厂:
@Autowired
private ConfigurationProperties props;
@Bean
public CachingConnectionFactory defaultConnectionFactory() {
CachingConnectionFactory cf = new CachingConnectionFactory();
cf.setAddresses(this.props.getAddresses());
cf.setUsername(this.props.getUsername());
cf.setPassword(this.props.getPassword());
cf.setVirtualHost(this.props.getVirtualHost());
return cf;
}
@Bean
public LocalizedQueueConnectionFactory queueAffinityCF(
@Qualifier("defaultConnectionFactory") ConnectionFactory defaultCF) {
return new LocalizedQueueConnectionFactory(defaultCF,
StringUtils.commaDelimitedListToStringArray(this.props.getAddresses()),
StringUtils.commaDelimitedListToStringArray(this.props.getAdminUris()),
StringUtils.commaDelimitedListToStringArray(this.props.getNodes()),
this.props.getVirtualHost(), this.props.getUsername(), this.props.getPassword(),
false, null);
}请注意,前三个参数是 、 和 的数组。
这些是位置性的,因为当容器尝试连接到队列时,它使用管理 API 来确定哪个节点是队列的引线,并连接到与该节点位于同一数组位置的地址。addressesadminUrisnodes
从版本 3.0 开始,RabbitMQ 不再用于访问 Rest API。
相反,默认情况下,如果在类路径上,则使用 from Spring Webflux;否则使用 a。http-clientWebClientspring-webfluxRestTemplate |
要添加到类路径,请执行以下操作:WebFlux
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>compile 'org.springframework.amqp:spring-rabbit'您还可以通过实现和重写其他 REST 方法以及可选的方法来使用其他 REST 技术。LocalizedQueueConnectionFactory.NodeLocatorcreateClient, ``restCallclose
lqcf.setNodeLocator(new NodeLocator<MyClient>() {
@Override
public MyClient createClient(String userName, String password) {
...
}
@Override
public HashMap<String, Object> restCall(MyClient client, URI uri) {
...
});
});该框架提供 和 ,其默认值如上所述。WebFluxNodeLocatorRestTemplateNodeLocator
因此(使用队列名称进行查找),仅当容器配置为侦听单个队列时,才能使用 。LocalizedQueueConnectionFactory |
| 必须在每个节点上启用 RabbitMQ 管理插件。 |
此连接工厂适用于长期连接,例如 .
它不适用于短连接使用,例如,因为在建立连接之前调用 REST API 的开销。
此外,对于发布操作,队列是未知的,并且消息无论如何都会发布到所有集群成员,因此查找节点的逻辑几乎没有价值。SimpleMessageListenerContainerRabbitTemplate |
从版本 3.0 开始,RabbitMQ 不再用于访问 Rest API。
相反,默认情况下,如果在类路径上,则使用 from Spring Webflux;否则使用 a。http-clientWebClientspring-webfluxRestTemplate |
发布者确认并返回
通过将属性设置为“true”并将属性设置为“true”,支持确认(具有相关性)和返回的消息。CachingConnectionFactorypublisherConfirmTypeConfirmType.CORRELATEDpublisherReturns
设置这些选项后,工厂创建的实例将包装在 中,用于方便回调。
当获得这样的通道时,客户端可以向 .
该实现包含用于将确认或返回路由到相应侦听器的逻辑。
以下各节将进一步介绍这些功能。ChannelPublisherCallbackChannelPublisherCallbackChannel.ListenerChannelPublisherCallbackChannel
另请参阅 Correlated Publisher Confirming and Returns 和 Scoped Operations。simplePublisherConfirms
| 有关更多背景信息,请参阅 RabbitMQ 团队的博客文章,标题为“发布者确认简介”。 |
| 有关更多背景信息,请参阅 RabbitMQ 团队的博客文章,标题为“发布者确认简介”。 |
连接和通道侦听器
连接工厂支持注册和实现。
这允许您接收连接和通道相关事件的通知。
(A 用于在建立连接时执行声明 - 有关更多信息,请参阅交换、队列和绑定的自动声明)。
以下列表显示了接口定义:ConnectionListenerChannelListenerConnectionListenerRabbitAdminConnectionListener
@FunctionalInterface
public interface ConnectionListener {
void onCreate(Connection connection);
default void onClose(Connection connection) {
}
default void onShutDown(ShutdownSignalException signal) {
}
}从版本 2.0 开始,可以为对象提供实例,以便在连接阻止和取消阻止事件时收到通知。
下面的示例演示 ChannelListener 接口定义:org.springframework.amqp.rabbit.connection.Connectioncom.rabbitmq.client.BlockedListener
@FunctionalInterface
public interface ChannelListener {
void onCreate(Channel channel, boolean transactional);
default void onShutDown(ShutdownSignalException signal) {
}
}请参阅发布是异步的 — 如何检测成功和失败,了解您可能希望注册 .ChannelListener
记录通道关闭事件
版本 1.5 引入了一种机制,使用户能够控制日志记录级别。
使用默认策略来记录通道关闭,如下所示:AbstractConnectionFactory
-
不记录正常通道关闭 (200 OK)。
-
如果通道由于被动队列声明失败而关闭,则会在 DEBUG 级别记录该通道。
-
如果一个频道因为排他性消费者条件而被拒绝而关闭,则该频道将被记录在 调试级别(从 3.1 开始,以前是 INFO)。
basic.consume -
所有其他记录在 ERROR 级别。
若要修改此行为,可以将自定义项注入到 in its 属性中。ConditionalExceptionLoggerCachingConnectionFactorycloseExceptionLogger
此外,现在是公开的,允许它被子类化。AbstractConnectionFactory.DefaultChannelCloseLogger
另请参阅消费者事件。
运行时缓存属性
从 1.6 版开始,现在通过该方法提供缓存统计信息。
这些统计信息可用于优化缓存,以便在生产环境中对其进行优化。
例如,高水位线可用于确定是否应增加缓存大小。
如果它等于缓存大小,则可能需要考虑进一步增加。
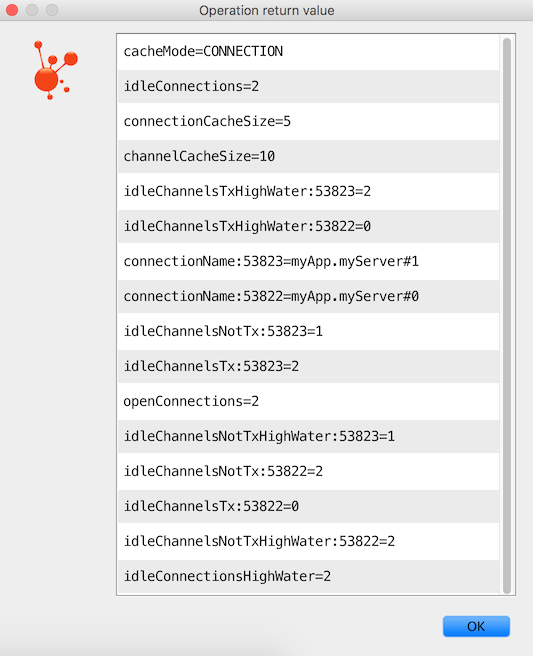
下表描述了这些属性:CachingConnectionFactorygetCacheProperties()CacheMode.CHANNEL
| 财产 | 意义 |
|---|---|
connectionName |
由 生成的连接的名称。 |
channelCacheSize |
当前配置的允许空闲的最大通道数。 |
localPort |
连接的本地端口(如果可用)。 这可用于与 RabbitMQ 管理 UI 上的连接和通道相关联。 |
idleChannelsTx |
当前处于空闲(缓存)状态的事务通道数。 |
idleChannelsNotTx |
当前处于空闲(缓存)状态的非事务性通道数。 |
idleChannelsTxHighWater |
并发空闲(缓存)的事务通道的最大数量。 |
idleChannelsNotTxHighWater |
非事务通道的最大数量已同时处于空闲状态(缓存)。 |
下表描述了这些属性:CacheMode.CONNECTION
| 财产 | 意义 |
|---|---|
connectionName:<localPort> |
由 生成的连接的名称。 |
openConnections |
表示与代理的连接的连接对象的数量。 |
channelCacheSize |
当前配置的允许空闲的最大通道数。 |
connectionCacheSize |
当前配置的允许空闲的最大连接数。 |
idleConnections |
当前处于空闲状态的连接数。 |
idleConnectionsHighWater |
并发空闲的最大连接数。 |
idleChannelsTx:<localPort> |
此连接当前处于空闲(缓存)状态的事务通道数。
您可以使用属性名称的一部分与 RabbitMQ 管理 UI 上的连接和通道相关联。 |
idleChannelsNotTx:<localPort> |
此连接当前处于空闲(缓存)状态的非事务性通道数。
属性名称的部分可用于与 RabbitMQ 管理 UI 上的连接和通道相关联。 |
idleChannelsTxHighWater:<localPort> |
并发空闲(缓存)的事务通道的最大数量。 属性名称的 localPort 部分可用于与 RabbitMQ 管理 UI 上的连接和通道相关联。 |
idleChannelsNotTxHighWater:<localPort> |
非事务通道的最大数量已同时处于空闲状态(缓存)。
您可以使用属性名称的一部分与 RabbitMQ 管理 UI 上的连接和通道相关联。 |
属性 ( 或 ) 也包括在内。cacheModeCHANNELCONNECTION
| 财产 | 意义 |
|---|---|
connectionName |
由 生成的连接的名称。 |
channelCacheSize |
当前配置的允许空闲的最大通道数。 |
localPort |
连接的本地端口(如果可用)。 这可用于与 RabbitMQ 管理 UI 上的连接和通道相关联。 |
idleChannelsTx |
当前处于空闲(缓存)状态的事务通道数。 |
idleChannelsNotTx |
当前处于空闲(缓存)状态的非事务性通道数。 |
idleChannelsTxHighWater |
并发空闲(缓存)的事务通道的最大数量。 |
idleChannelsNotTxHighWater |
非事务通道的最大数量已同时处于空闲状态(缓存)。 |
| 财产 | 意义 |
|---|---|
connectionName:<localPort> |
由 生成的连接的名称。 |
openConnections |
表示与代理的连接的连接对象的数量。 |
channelCacheSize |
当前配置的允许空闲的最大通道数。 |
connectionCacheSize |
当前配置的允许空闲的最大连接数。 |
idleConnections |
当前处于空闲状态的连接数。 |
idleConnectionsHighWater |
并发空闲的最大连接数。 |
idleChannelsTx:<localPort> |
此连接当前处于空闲(缓存)状态的事务通道数。
您可以使用属性名称的一部分与 RabbitMQ 管理 UI 上的连接和通道相关联。 |
idleChannelsNotTx:<localPort> |
此连接当前处于空闲(缓存)状态的非事务性通道数。
属性名称的部分可用于与 RabbitMQ 管理 UI 上的连接和通道相关联。 |
idleChannelsTxHighWater:<localPort> |
并发空闲(缓存)的事务通道的最大数量。 属性名称的 localPort 部分可用于与 RabbitMQ 管理 UI 上的连接和通道相关联。 |
idleChannelsNotTxHighWater:<localPort> |
非事务通道的最大数量已同时处于空闲状态(缓存)。
您可以使用属性名称的一部分与 RabbitMQ 管理 UI 上的连接和通道相关联。 |
RabbitMQ 自动连接/拓扑恢复
自 Spring AMQP 的第一个版本以来,该框架在代理发生故障时提供了自己的连接和通道恢复。
此外,如配置代理中所述,当重新建立连接时,将重新声明任何基础架构 Bean(队列和其他)。
因此,它不依赖于库现在提供的自动恢复。
默认情况下,该 已启用自动恢复。
这两种恢复机制之间存在一些不兼容之处,因此,默认情况下,Spring 将基础上的属性设置为 。
即使属性是 ,Spring 也会通过立即关闭任何恢复的连接来有效地禁用它。RabbitAdminamqp-clientamqp-clientautomaticRecoveryEnabledRabbitMQ connectionFactoryfalsetrue
| 缺省情况下,只有定义为 Bean 的元素(队列、交换、绑定)才会在连接失败后重新声明。 有关如何更改该行为,请参阅恢复自动删除声明。 |
| 缺省情况下,只有定义为 Bean 的元素(队列、交换、绑定)才会在连接失败后重新声明。 有关如何更改该行为,请参阅恢复自动删除声明。 |